LAST UPDATED ON: SEPTEMBER 16, 2024
CPU Scheduling in Operating System
CPU scheduling is a process that allows one process to use the CPU while the execution of another process is on hold(in waiting state) due to unavailability of any resource like I/O etc, thereby making full use of CPU. The aim of CPU scheduling is to make the system efficient, fast, and fair.
Whenever the CPU becomes idle, the operating system must select one of the processes in the ready queue to be executed. The selection process is carried out by the short-term scheduler (or CPU scheduler). The scheduler selects from among the processes in memory that are ready to execute and allocates the CPU to one of them.
CPU Scheduling: Dispatcher
Another component involved in the CPU scheduling function is the Dispatcher. The dispatcher is the module that gives control of the CPU to the process selected by the short-term scheduler. This function involves:
- Switching context
- Switching to user mode
- Jumping to the proper location in the user program to restart that program from where it left last time.
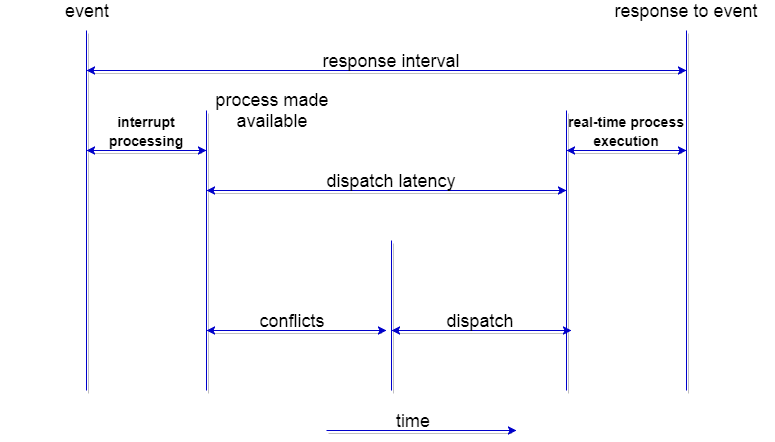
The dispatcher should be as fast as possible, given that it is invoked during every process switch. The time taken by the dispatcher to stop one process and start another process is known as the Dispatch Latency. Dispatch Latency can be explained using the below figure:
Types of CPU Scheduling
CPU scheduling decisions may take place under the following four circumstances:
-
When a process switches from the running state to the waiting state(for I/O request or invocation of wait for the termination of one of the child processes).
-
When a process switches from the running state to the ready state (for example, when an interrupt occurs).
-
When a process switches from the waiting state to the ready state(for example, completion of I/O).
-
When a process terminates.
In circumstances 1 and 4, there is no choice in terms of scheduling. A new process(if one exists in the ready queue) must be selected for execution. There is a choice, however in circumstances 2 and 3.
When Scheduling takes place only under circumstances 1 and 4, we say the scheduling scheme is non-preemptive; otherwise, the scheduling scheme is preemptive.
1. Non-Preemptive Scheduling
Under non-preemptive scheduling, once the CPU has been allocated to a process, the process keeps the CPU until it releases the CPU either by terminating or by switching to the waiting state.
This scheduling method is used by the Microsoft Windows 3.1 and by the Apple Macintosh operating systems.
It is the only method that can be used on certain hardware platforms because It does not require the special hardware(for example a timer) needed for preemptive scheduling.
In non-preemptive scheduling, it does not interrupt a process running CPU in the middle of the execution. Instead, it waits till the process completes its CPU burst time, and then after that it can allocate the CPU to any other process.
Some Algorithms based on non-preemptive scheduling are: Shortest Job First (SJF basically non-preemptive) Scheduling and Priority (non- preemptive version) Scheduling, etc.
![cpu scheduling]()
2. Preemptive Scheduling
In this type of Scheduling, the tasks are usually assigned with priorities. At times it is necessary to run a certain task that has a higher priority before another task although it is running. Therefore, the running task is interrupted for some time and resumed later when the priority task has finished its execution.
Thus this type of scheduling is used mainly when a process switches either from running state to ready state or from waiting state to ready state. The resources (that is CPU cycles) are mainly allocated to the process for a limited amount of time and then are taken away, and after that, the process is again placed back in the ready queue in the case if that process still has a CPU burst time remaining. That process stays in the ready queue until it gets the next chance to execute.
Some Algorithms that are based on preemptive scheduling are Round Robin Scheduling (RR), Shortest Remaining Time First (SRTF), Priority (preemptive version) Scheduling, etc.
![Preemptive Scheduling]()
CPU Scheduling: Scheduling Criteria
There are many different criteria to check when considering the "best" scheduling algorithm, they are:
1. CPU Utilization
To make out the best use of the CPU and not to waste any CPU cycle, the CPU would be working most of the time(Ideally 100% of the time). Considering a real system, CPU usage should range from 40% (lightly loaded) to 90% (heavily loaded.)
2. Throughput
It is the total number of processes completed per unit of time or rather says the total amount of work done in a unit of time. This may range from 10/second to 1/hour depending on the specific processes.
3. Turnaround Time
It is the amount of time taken to execute a particular process, i.e. The interval from the time of submission of the process to the time of completion of the process(Wall clock time).
4. Waiting Time
The sum of the periods spent waiting in the ready queue amount of time a process has been waiting in the ready queue to acquire get control on the CPU.
5. Load Average
It is the average number of processes residing in the ready queue waiting for their turn to get into the CPU.
6. Response Time
Amount of time it takes from when a request was submitted until the first response is produced. Remember, it is the time till the first response and not the completion of process execution(final response).
In general CPU utilization and Throughput are maximized and other factors are reduced for proper optimization.
Scheduling Algorithms
To decide which process to execute first and which process to execute last to achieve maximum CPU utilization, computer scientists have defined some algorithms, they are:
-
First Come First Serve(FCFS) Scheduling
-
Shortest-Job-First(SJF) Scheduling
-
Priority Scheduling
-
Round Robin(RR) Scheduling
-
Multilevel Queue Scheduling
-
Multilevel Feedback Queue Scheduling
-
Shortest Remaining Time First (SRTF)
-
Longest Remaining Time First (LRTF)
-
Highest Response Ratio Next (HRRN)
We will be discussing all the scheduling algorithms, one by one, in detail in the next tutorials.