Recently while I was learning about Word2Vec, I realized there are so many features and important information about this great finding but it is all scattered. I had to read 10 different blogs before completely understanding the logic. If you are like me and love to supplement the paper reading with blogs, this is the right place.
What is Word2Vec?
If you are an NLP fan or you have just started your journey, you must have come across this. Let me first take you to the past and introduce some other topics to build the intuition.
If you want to do crazy things with text including sentiment analysis, question-answering, text similarity, topic modeling, and what not, you are going to feed words/sentences/documents to the model.
But! the machine doesn't understand the text right? So you would convert it into a machine-readable form. The word vector is the thing you are looking for.
Word Vector is the representation of words in the vector form. Well, you can just encode the words and match the encoded vectors but that won't solve the purpose. Imagine having 1 Million words in the vocabulary and then encoding all those words to pass to the network. Why not learn to encode similarities to vectors?
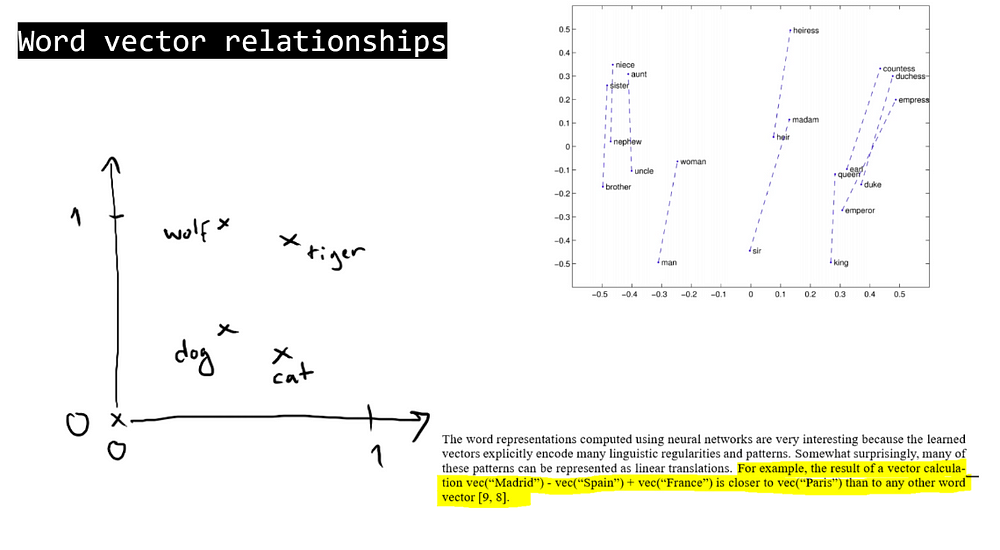
Word representations in vector space (2-D)
Word representations in vector space (3-D)
Crazy Computation! Not Possible(Even if it is why would I kill my machine with heavy math and 0's?)
What before Word2Vec?
Before Word2Vec N-grams were used to capture the meaning of the word given n accompanying words before context word but N-grams cannot capture the context.
The overall probability would be P(current_word|n_words).
To enhance similarities we need embeddings. Don’t just cluster words, seek representation that can capture the degree of similarity.
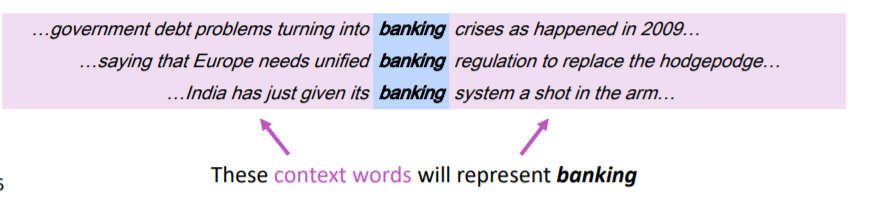
Context includes words in a fixed window around the word in a text
What's the measurement of quality in Word2Vec?
Its the similarity of words in a task.
Advantages:
-
Computationally efficient
-
Accurate
-
Performs well on finding the semantic and syntactic similarity
Okay, but how does these **WORD VECTORS WORK**?
Each word is encoded in a vector(as a number represented in multiple-dimension) to be matched with vectors of words that appear in a similar context. Hence a dense vector is formed for the text. The vectors are based on the features.

Word vectors are sometimes called word embeddings or word representations. They are a distributed representation

See how related words are around ‘expect’, it’s because those word vectors are similar
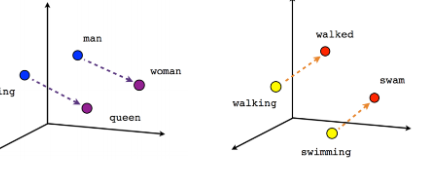
Word Embedding gives the meanings of words with the help of vectors. Subtractions of vectors of some words gives rise to meaningful relationship.
For Example:
King-Man+Woman=Queen
(Vking-VMan+VWoman=VQueen, where V=Vector)
By using word embedding we use a fully connected layer and its weights are called embedding weights(whose values are learned during training the model just like the other layers like Dense, CNN etc are learned).
And this embedding weight matrix turns out to be a lookup table.
Without word embedding, you’d encode the text and then multiply that with the hidden layer. For 200 words you will one hot encode and then multiply with the hidden layer. That will give you mostly 0’s in the output. How inefficient is that?
Word Embedding comes to rescue. Since multiplication of any One hot encoded vector with weight matrix is the corresponding row itself, we just assign unique integers to word and then take the corresponding row from the lookup table. Thus there's no need to multiply.
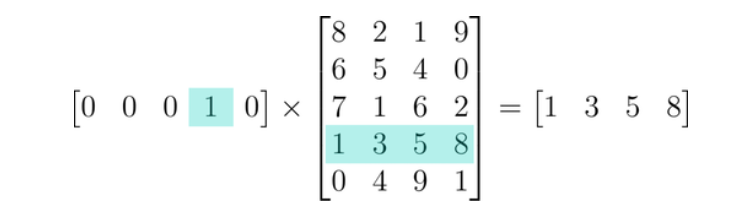
Multiplying any OHE vector gives just the corresponding row.
So an embedding layer is a layer having embedding weights that are learned during training.
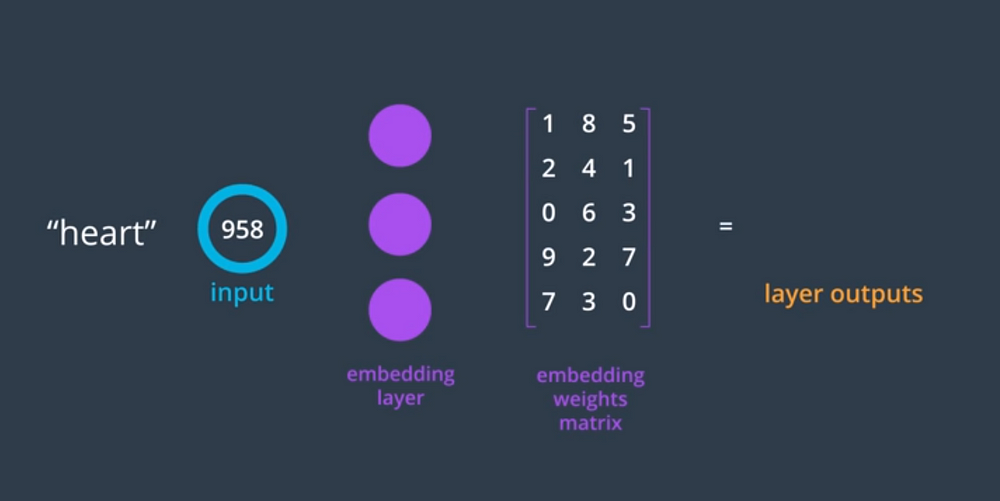
From the Udacity's deep learning nano degree
Say there is a word heart whose index is 958. Now the 958th row of the embedding matrix will be the output and will be moved forward to the hidden layer.
These weights in the lookup table are just vector representations of words. Columns in these matrices represent the embedding dimension. Any word having the same meaning has the same representation.
Finally, let's discuss Word2Vec
Word2Vec model uses this concept of embedding and lookup. Based on the word of interest and context it understands and learns the weights to prepare the matrix. This prepared matrix is embedding which understands the similarity in words.
The words in a similar context have similar representation. Word2Vec find these similarities and relationships between them during training and hence prepare a master vector representation called embedding.
Similar words are near each other and dissimilar are far in the representation.
This is all about Word Vectors, Embeddings, and Word2Vec. Drop your questions in the comments.
External References:
-
http://web.stanford.edu/class/cs224n/slides/cs224n-2020-lecture01-wordvecs1.pdf
-
http://jalammar.github.io/illustrated-word2vec/
You may also like: